
QUIZ QUESTION & ANSWER JUARAGCP
Questions
Question 1.
You are preparing a training session for junior data scientists at “DataWise Analytics” on core Google Cloud services relevant to their work. You want to assess their understanding of how these services interact and their specific functionalities within the ML workflow.
Which Google Cloud service is MOST directly associated with providing a managed environment for interactive machine learning development using JupyterLab notebooks?
- Cloud KMS
- Cloud Storage
- Vertex AI Workbench
- Vertex AI Training
Question 2.
You are preparing a training session for junior data scientists at “DataWise Analytics” on core Google Cloud services relevant to their work. You want to assess their understanding of how these services interact and their specific functionalities within the ML workflow.
Which Google Cloud service is MOST directly associated with storing and retrieving large amounts of unstructured data, such as image datasets or model checkpoints?
- Vertex AI Training
- Cloud KMS
- Vertex AI Workbench
- Cloud Storage
Question 3.
You are preparing a training session for junior data scientists at “DataWise Analytics” on core Google Cloud services relevant to their work. You want to assess their understanding of how these services interact and their specific functionalities within the ML workflow.
Which Google Cloud service is MOST directly associated with securely storing and managing sensitive data, including encryption keys, often used for model artifacts or training data?
- Cloud KMS
- Cloud Storage
- Vertex AI Training
- Vertex AI Workbench
Question 4.
You are a product manager at “Visionary Designs” developing a new AI-powered marketing platform. A key feature will allow users to upload a combination of images and text to generate marketing copy and social media posts automatically. Which aspect of Gemini’s capabilities is MOST crucial for enabling this feature?
- Gemini’s ability to perform complex mathematical calculations.
- Gemini’s ability to access and analyze data from various online sources.
- Gemini’s multimodality, allowing it to process and understand both images and text.
- Gemini’s integration with Google Cloud Storage for storing and retrieving large files.
Question 5.
You are a machine learning engineer at “DataWise Analytics.” You need to access your JupyterLab notebook instance on Vertex AI Workbench to continue working on a model. You are starting from the Google Cloud Console.
Place the following steps in the correct order to access your JupyterLab environment on Vertex AI Workbench:
- Navigate to the Vertex AI section in the Google Cloud Console.
- Click the “OPEN JUPYTERLAB” link for your desired instance.
- Select the appropriate project in the Google Cloud Console.
- Choose the “Workbench” option (or similar wording) from the Vertex AI menu.
Which of the following sequences is the CORRECT order?
- 3, 1, 4, 2
- 4, 1, 2, 3
- 1, 4, 3, 2
- 3, 2, 1, 4
- 2, 4, 1, 3
Question 6.
You are a machine learning engineer at “DataWise Analytics.” Your team is transitioning to using Vertex AI for all machine learning projects. You need to explain to a new team member the overall capabilities of Vertex AI, particularly in the context of their day-to-day work, which will involve using Vertex AI Workbench and JupyterLab for model development. You want to give them a high-level overview of what Vertex AI offers beyond just the notebook environment they will be using.
Which of the following BEST describes the capabilities of Google Cloud’s Vertex AI platform, emphasizing its role in the broader machine learning workflow beyond just providing a notebook environment?
- A. It is a platform for building, training, deploying, and managing machine learning models, including both custom models and pre-trained models, and integrates closely with environments like Vertex AI Workbench.
- B. It is a platform solely for storing and managing large datasets used in machine learning, which they will access from their JupyterLab notebooks.
- C. It is a platform specifically designed for natural language processing tasks, offering pre-trained models for text classification and generation, which they can utilize within their notebooks.
- D. It is a platform dedicated to providing infrastructure for running deep learning experiments, including virtual machines with GPUs and TPUs, which they can connect to from their JupyterLab instances.
Question 7.
You are part of a rapid prototyping team at “Visionary Designs” tasked with quickly evaluating the potential of Gemini’s image generation capabilities for a new marketing campaign. You’ve been given a partially completed Python script that uses the Vertex AI API and need to understand its core functionality before integrating it into a larger system. The script is designed for rapid testing and assumes certain configurations are already in place.
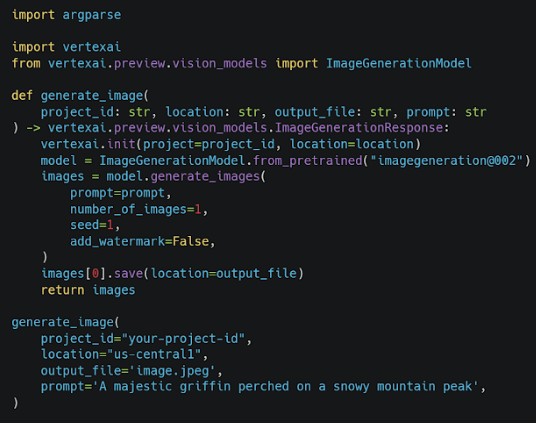
What is the PRIMARY purpose of the provided Python code snippet?
- To fine-tune the “
imagegeneration@002” model with custom training data specific to the marketing campaign. - To generate a single image from a textual description using a pre-trained Gemini model for initial visual exploration.
- To deploy a production-ready image generation service to a scalable endpoint on Vertex AI.
- To create a batch prediction job to generate multiple variations of a marketing image based on different prompts.
Question 8.
You are a cloud engineer at “Innovate Inc.” tasked with automating the deployment of Compute Engine instances for a new machine learning project. Your senior developer has instructed you to use only the gcloud CLI from your Windows laptop’s command prompt. You must create an instance with the following specifications: an n1-standard-2 machine type, 2 vCPUs, 8 GB of RAM, a 100 GB standard persistent disk as the boot disk, and located in the us-west1-b zone. The instance should also have a network tag called ml-training.
Which of the following gcloud command-line instructions correctly creates this Compute Engine instance?
gcloud compute instances create ml-instance --machine-type n1-standard-2 --boot-disk-size 100GB --zone us-west1-b --network-interface network-tier=STANDARD,tags=ml-traininggcloud compute instances create ml-instance --machine-type n1-standard-2 --boot-disk-size 100GB --zone us-west1-b --network-tag ml-traininggcloud compute instances create ml-instance --machine-type n1-standard-2 --boot-disk-size 100GB --zone us-west1-b --boot-disk-type pd-standard --network-tags ml-traininggcloud compute instances create ml-instance --machine-type n1-standard-2 --boot-disk-size 100GB --zone us-west1-b --disk type=pd-standard,size=100GB --network-tags ml-traininggcloud compute instances create ml-instance --machine-type n1-standard-2 --boot-disk-size 100GB --zone us-west1-b --tags ml-training
Question 9.
You are a cloud operations engineer at “Global Data Solutions.” The company is migrating its financial transaction data to a new data lake in Google Cloud Storage. This data is highly sensitive and needs to be managed according to strict regulatory compliance requirements. You are responsible for configuring a Cloud Storage bucket named phoenix-analytics-lake to meet these needs. The data will be accessed quarterly by a team of financial analysts, and older data must be retained for auditing purposes for a specific period before permanent deletion. Access control must be strictly enforced to comply with data privacy regulations.
Which combination of configurations BEST addresses the following requirements:
- Data that is older than 90 days should be transitioned to a less expensive storage tier suitable for infrequent access.
- Access to the data should be strictly limited to the finance department, managed as a group.
- Data that is older than 1095 days (3 years) should be permanently deleted to comply with data retention policies.
- E. Lifecycle rules with transitions to Nearline storage after 90 days and deletion after 1095 days, combined with Access Control Lists (ACLs) granting read access to individual users in the finance department.
- D. Lifecycle rules with transitions to Coldline storage after 30 days and deletion after 730 days, combined with service account keys granted to the finance department.
- A. Lifecycle rules with transitions to Coldline storage after 90 days and deletion after 1095 days, combined with IAM roles granting read access to the finance department’s Google Group.
- C. Lifecycle rules with transitions to Archive storage after 90 days and deletion after 1095 days, combined with individual IAM user accounts granted read access.
- B. Lifecycle rules with transitions to Nearline storage after 90 days and deletion after 1095 days, combined with IAM roles granting write access to the finance department’s Google Group.
Question 10.
“Innovate Inc.” is developing a new AI-driven customer support system. This system will allow customers to describe their technical issues in text and optionally upload images of error messages or device setups. The system uses Gemini. You have a very brief 8-second opportunity to explain to the customer support team how Gemini helps the system understand customer issues.
- “Gemini is the AI that allows the system to understand both your text descriptions and any images you upload to provide more accurate support.”
- “Gemini is a large language model that generates automated responses to common customer questions.”
- “Gemini is a cloud-based platform that hosts the customer support system and ensures its scalability.”
- “Gemini is an AI that analyzes customer sentiment and automatically routes support tickets to the appropriate agents.”
Question 11.
“Swift Solutions Inc.” is developing a new mobile app that allows users to quickly generate personalized social media graphics. The app needs to generate images based on user-provided text prompts in real-time. The company wants to leverage AI for this feature but needs a solution that is both cost-effective and provides fast response times to ensure a good user experience. Which Gemini model would be MOST suitable for this use case?
- PaLM 2
- Gemini Flash
- Gemini Pro
- Imagen
Question 12.
You are a developer at “Cosmic Insights Inc.” tasked with integrating Gemini Pro into a new research application. You need to test the Gemini API directly from your Cloud Shell environment. Your initial test will involve sending a simple prompt to the gemini-1.0-pro model.
You are working in Cloud Shell and need to call the Gemini API. You have already enabled the necessary APIs via the Cloud Console. Which of the following sequences of steps is the MOST accurate way to call the gemini-1.0-pro LLM with the prompt “What are the benefits of using large language models?” and display the response?
- 1. Authenticate using gcloud compute instances create … with a service account.
2. Construct a curl command with the correct headers and JSON payload.
3. Send the curl command to the Gemini API. - 1. Obtain an access token using gcloud auth application-default print-access-token.
2. Construct a curl command with the correct headers (including the access token and Content-Type) and the JSON payload (including the model name and prompt).
3. Send the curl command to the appropriate Gemini API endpoint. - 1. Construct a curl command with the model name and prompt in the URL.
2. Authenticate using gcloud auth application-default login.
3. Send the curl command. - 1. Use the gemini command-line tool (if it existed).
2. Provide the prompt as an argument to the command.
Question 13.
You are a data engineer at “Cosmic Insights Inc.” setting up a new data warehouse in BigQuery. You need to create a dataset named gemini_demo in the US multi-region location. You are using the bq command-line tool.
Which of the following bq commands will correctly create the dataset with the specified configuration?
bq mk --dataset --location=US gemini_demobq mk --dataset --location=US --dataset_name=gemini_demobq mk --dataset --location=MULTI_REGION:US gemini_demobq mk --dataset --location=us --dataset_id=gemini_demobq mk --dataset --region=US gemini_demo
Question 14.
You are a data scientist working with a vast dataset of customer reviews in BigQuery. You want to use the power of generative AI models to analyze the sentiment of these reviews and generate summaries.
Which BigQuery ML function allows you to directly utilize remote Gen AI models for language tasks such as content generation and summarization?
ML.FORECASTML.PREDICTML.GENERATE_TEXTML.DETECT_ANOMALIES
Question 15.
You are leading a workshop on prompt engineering for the marketing team at “Global Content Creators.” Several team members are new to the concept of generative AI and its capabilities. You want to clearly explain the concept of zero-shot prompting, emphasizing its reliance on the model’s pre-existing knowledge.
Which of the following BEST describes a zero-shot prompt, suitable for explaining the concept to a team unfamiliar with generative AI?
- A prompt that includes a few examples to guide the model’s generation, like showing it a few different ad slogans and asking it to create a new one.
- A prompt that asks the model to perform a task without giving any specific examples, relying on its general knowledge, like asking it to summarize a topic.
- prompt that provides a large dataset of text without specific instructions, like giving the model a whole encyclopedia and asking it to write a story.
- prompt that gives the model one example of the desired input-output pair, like showing it one translated sentence and asking it to translate another.
Question 16.
You are leading a workshop on prompt engineering for the marketing team at “Global Content Creators.” Several team members are new to the concept of generative AI and its capabilities. You want to clearly explain the concept of zero-shot prompting, emphasizing its reliance on the model’s pre-existing knowledge.
Which of the following BEST describes a zero-shot prompt, suitable for explaining the concept to a team unfamiliar with generative AI?
- A prompt that includes a few examples to guide the model’s generation, like showing it a few different ad slogans and asking it to create a new one.
- A prompt that asks the model to perform a task without giving any specific examples, relying on its general knowledge, like asking it to summarize a topic.
- A prompt that provides a large dataset of text without specific instructions, like giving the model a whole encyclopedia and asking it to write a story.
- A prompt that gives the model one example of the desired input-output pair, like showing it one translated sentence and asking it to translate another.
Question 17.
You are a machine learning engineer at “Innovate Inc.” leading a team developing a new image recognition model on GCP. Your project is in its early stages, and you have a limited budget. You’re concerned about potential cost overruns as your team scales up experiments and data processing. You need to ensure that you are aware of spending and can take action if costs exceed expectations. What is the MOST proactive step you can take to manage and control your project’s cloud spending in this situation?
- Regularly check the Billing section in the console, perhaps daily or weekly.
- Set up billing alerts to notify you when spending reaches a certain threshold that you define.
- Export billing data to BigQuery for detailed analysis of spending trends.
- Contact Google Cloud sales to negotiate a discounted rate for your project.
Question 18.
You are introducing Google Colab (https://colab.google.com/) to a team of marketing analysts who are transitioning from using spreadsheets for data analysis. You want to highlight the different types of content they can include in a Colab notebook to create comprehensive and interactive reports.
When explaining the structure and capabilities of Colab notebooks to your team, which of the following components would you emphasize as being typically found within a notebook? (Select all that apply)
- Code cells, where they can write and execute Python or R code for data manipulation and analysis.
- Output of executed code, including tables, charts, and other visualizations generated by their code.
- Version control history, showing all the changes made to the notebook over time.
- Visualizations (plots, graphs) created from their data, allowing for interactive exploration of results.
- Markdown cells, where they can add formatted text, headings, and explanations to document their analysis.
Question 19.
You are a data engineer at “AI Innovations Inc.” You have trained a machine learning model on your local machine and now need to upload the trained model file (data.csv) to a Cloud Storage bucket so that it can be deployed on Vertex AI. The bucket is named my-ml-bucket. You are working from your local machine’s terminal.
Which gsutil command should you use to copy the file data.csv from your local machine to the my-ml-bucket Cloud Storage bucket?
gsutil cp data.csv gs://my-ml-bucketgsutil copy data.csv gs://my-ml-bucketgsutil put data.csv gs://my-ml-bucketgsutil mv data.csv gs://my-ml-bucket
Question 20.
“AI Innovations Inc.” is developing a new application that uses Gemini Pro to analyze images stored in Cloud Storage. The images are uploaded by users and are accessed frequently for the first 30 days, then accessed rarely afterwards for storage-only purposes. The company is looking for ways to reduce storage costs associated with this application. Which Cloud Storage class would be MOST cost-effective for storing these images long-term?
- A. Standard
- D. Archive
- C. Coldline
- B. Nearline
Question 21.
You are working on a Python script named my_script.py in your Cloud Shell environment. You’ve made some changes to the script using Vim and are ready to save your work and exit Vim.
You are editing the file my_script.py in Vim within Cloud Shell. You want to save the file and exit Vim. Which command should you type and press Enter?
Ctrl+Sand then:q:saveand then:quitctrl + o + x:wq!
Answers
Answer 1.
The correct answer is:
- Vertex AI Workbench
Explanation:
- Vertex AI Workbench provides a managed JupyterLab environment specifically designed for interactive machine learning development on Google Cloud.
- Cloud KMS (Key Management Service) is used for encryption key management and security, not for ML development.
- Cloud Storage is a scalable object storage service that is often used to store datasets and ML models but does not provide an interactive development environment.
- Vertex AI Training is focused on training ML models at scale, but it does not provide a JupyterLab environment for development.
Thus, Vertex AI Workbench is the most directly associated service for interactive ML development using JupyterLab notebooks. 🚀
Answer 2.
The correct answer is:
- Cloud Storage
Explanation:
- Cloud Storage is a highly scalable object storage service designed for storing and retrieving large amounts of unstructured data, such as image datasets, model checkpoints, training data, and ML artifacts.
- Vertex AI Training is used for training ML models but does not primarily serve as a storage solution.
- Cloud KMS (Key Management Service) is used for encryption key management and security, not for storing unstructured data.
- Vertex AI Workbench provides a managed JupyterLab environment for interactive ML development, but it does not specialize in large-scale data storage.
Thus, Cloud Storage is the most appropriate choice for storing and retrieving large amounts of unstructured data. ✅
Answer 3.
The correct answer is:
- Cloud KMS (Key Management Service)
Explanation:
- Cloud KMS (Key Management Service) is specifically designed for securely storing and managing encryption keys used to protect sensitive data, such as model artifacts, training data, and other confidential information.
- Cloud Storage is used for storing unstructured data but does not manage encryption keys directly (though it can integrate with Cloud KMS for encryption).
- Vertex AI Training is used for training ML models but does not handle encryption or key management.
- Vertex AI Workbench is an interactive ML development environment but does not provide encryption key management.
Thus, Cloud KMS is the most appropriate service for securely storing and managing sensitive data and encryption keys. ✅
Answer 4.
The correct answer is:
- Gemini’s multimodality, allowing it to process and understand both images and text.
Explanation:
- Gemini’s multimodality is the key capability that enables it to process and understand multiple types of data, including both images and text. This is crucial for an AI-powered marketing platform that generates content based on user-uploaded images and text.
- Complex mathematical calculations are not directly relevant to generating marketing copy and social media posts.
- Accessing and analyzing data from various online sources may help with research but is not essential for processing user-provided inputs.
- Integration with Google Cloud Storage is useful for storing images and text files but does not contribute to AI’s ability to generate content.
Thus, Gemini’s multimodal capabilities are the most crucial for enabling this feature. ✅
Answer 5.
The correct order is:
- 3, 1, 4, 2
Explanation:
To access your JupyterLab environment on Vertex AI Workbench from the Google Cloud Console, follow these steps in order:
- Select the appropriate project in the Google Cloud Console (Step 3).
- Before accessing any resources, ensure you’re in the correct Google Cloud project.
- Navigate to the Vertex AI section (Step 1).
- Vertex AI Workbench is part of the Vertex AI suite, so you need to go to this section in the Console.
- Choose the “Workbench” option (Step 4).
- This will list your available JupyterLab instances.
- Click “OPEN JUPYTERLAB” for your desired instance (Step 2).
- This launches the JupyterLab environment.
Thus, the correct sequence is:
3 → 1 → 4 → 2 ✅
Answer 6.
The correct answer is:
- A. It is a platform for building, training, deploying, and managing machine learning models, including both custom models and pre-trained models, and integrates closely with environments like Vertex AI Workbench.
Explanation:
Vertex AI is a comprehensive machine learning platform that supports the entire ML lifecycle, including:
- Model development (Vertex AI Workbench, JupyterLab)
- Training (Vertex AI Training)
- Deployment (Vertex AI Endpoints)
- Model management (Vertex AI Model Registry, MLOps tools)
- Integration with pre-trained models (Vertex AI AutoML, Generative AI capabilities)
Why the other options are incorrect:
- B: Vertex AI is not solely for storing and managing datasets—Cloud Storage is typically used for that purpose.
- C: While Vertex AI supports natural language processing (NLP), it is not exclusively designed for NLP tasks. It also supports computer vision, structured data, and other AI applications.
- D: Vertex AI does provide infrastructure for deep learning (GPUs/TPUs), but its capabilities go far beyond just running experiments—it also includes model training, deployment, and monitoring.
Thus, option A provides the most complete and accurate description of Vertex AI’s role in the ML workflow. ✅
Answer 7.
The correct answer is:
- To generate a single image from a textual description using a pre-trained Gemini model for initial visual exploration.
Explanation:
- The script loads a pre-trained image generation model (
imagegeneration@002) from Vertex AI and generates an image based on a textual prompt. - It does not perform fine-tuning with custom training data (eliminating option 1).
- The script is not setting up a scalable, production-ready endpoint—it is a simple function for generating a single image (eliminating option 3).
- It only generates one image at a time (
number_of_images=1), so it is not creating a batch prediction job (eliminating option 4).
Thus, the primary purpose of this script is to quickly generate an image from text using a pre-trained Gemini model for initial visual exploration. ✅
Answer 8.
The correct answer is:
gcloud compute instances create ml-instance --machine-type n1-standard-2 --boot-disk-size 100GB --zone us-west1-b --boot-disk-type pd-standard --network-tags ml-training
Explanation:
The correct gcloud CLI command should:
- Create a Compute Engine instance named
ml-instance. - Use the
n1-standard-2machine type, which has 2 vCPUs and 8 GB RAM. - Set the boot disk size to 100 GB with the
--boot-disk-size 100GBflag. - Use a standard persistent disk (
pd-standard) with--boot-disk-type pd-standard. - Specify the zone as
us-west1-b. - Attach a network tag called
ml-trainingusing--network-tags ml-training.
Why the other options are incorrect:
- Option 1:
--network-interface network-tier=STANDARD,tags=ml-trainingis incorrect becausetagsshould be specified separately with--network-tags.
- Option 2:
--network-tagis incorrect (should be--network-tagsin plural).
- Option 4:
--disk type=pd-standard,size=100GBis incorrect syntax for setting the boot disk type and size.
- Option 5:
- Missing
--boot-disk-type pd-standard, which ensures the disk is a standard persistent disk.
- Missing
Thus, the third option is correct ✅.
Answer 9.
The correct answer is:
- A. Lifecycle rules with transitions to Coldline storage after 90 days and deletion after 1095 days, combined with IAM roles granting read access to the finance department’s Google Group.
Explanation:
- Storage Lifecycle Management:
- Data older than 90 days should be moved to a lower-cost storage tier.
- Coldline storage is better than Nearline for data accessed quarterly, as Nearline is suited for data accessed monthly.
- Data older than 1095 days (3 years) should be permanently deleted for compliance.
- Access Control:
- IAM roles are the best practice for managing access control in Google Cloud, rather than ACLs or individual user accounts.
- Using a Google Group to manage the finance department ensures easier role assignment and scalability.
- Read access is appropriate for analysts who need to review data, but not modify it.
Why other options are incorrect:
- E: Uses ACLs instead of IAM roles (IAM is the best practice for managing permissions).
- D: Uses Coldline storage but deletes data after 730 days (2 years), which does not meet the 1095-day requirement. Also, service account keys should not be used for managing human user access.
- C: Grants read access to individual user accounts instead of a Google Group, making it harder to manage access efficiently.
- B: Grants write access instead of read access, which is not appropriate for financial analysts who only need to access the data.
Conclusion:
Option A correctly follows best practices for data lifecycle management and secure access control ✅.
Answer 10.
The correct answer is:
- “Gemini is the AI that allows the system to understand both your text descriptions and any images you upload to provide more accurate support.”
Explanation:
- Gemini is a multimodal AI model, meaning it can process and understand both text and images together.
- This is directly relevant to the AI-driven customer support system, which needs to analyze customer text descriptions and uploaded images to assist more accurately.
- The response is clear, concise, and directly addresses how Gemini improves customer support.
Why other options are incorrect:
❌ “Gemini is a large language model that generates automated responses to common customer questions.”
- While Gemini can generate responses, this option ignores its multimodal capability (processing both text and images).
❌ “Gemini is a cloud-based platform that hosts the customer support system and ensures its scalability.”
- Gemini is an AI model, not a cloud platform. Google Cloud provides hosting and scalability, but Gemini itself is not responsible for that.
❌ “Gemini is an AI that analyzes customer sentiment and automatically routes support tickets to the appropriate agents.”
- Sentiment analysis and ticket routing are possible AI applications, but this does not fully explain how Gemini helps the system understand issues from text and images.
Final Verdict:
The first option best describes Gemini’s multimodal capability in a simple, effective way within an 8-second explanation. ✅
Answer 11.
The correct answer is:
- Gemini Flash
Explanation:
- Gemini Flash models are optimized for speed and efficiency, making them ideal for real-time applications like generating social media graphics from text prompts.
- PaLM 2 is an older model and not specifically designed for image generation.
- Gemini Pro is more powerful but not as optimized for fast response times and cost-effectiveness as Gemini Flash.
- Imagen is a model specifically designed for high-quality image generation, but it may not be the most cost-effective or fastest option for real-time use.
Answer 12.
The correct answer is:
- “1. Obtain an access token using
gcloud auth application-default print-access-token.
2. Construct acurlcommand with the correct headers (including the access token andContent-Type) and the JSON payload (including the model name and prompt).
3. Send thecurlcommand to the appropriate Gemini API endpoint.”
Explanation:
- Authentication:
- You need an access token to authenticate with the Gemini API.
- The command
gcloud auth application-default print-access-tokenretrieves a valid token for authentication.
- Constructing the
curlrequest:- The request must include:
- The correct API endpoint.
- Headers:
Authorization: Bearer <ACCESS_TOKEN>Content-Type: application/json
- JSON payload specifying the model (
gemini-1.0-pro) and the prompt.
- The request must include:
- Sending the request:
- The
curlcommand sends the request to the Gemini API, and the response is displayed.
- The
Why the other options are incorrect?
- Option 1: Incorrect because
gcloud compute instances createis used to create VM instances, not for authentication with Gemini API. - Option 3: Incorrect because authentication must happen before sending the
curlcommand, and the model name should be in the JSON payload, not the URL. - Option 4: Incorrect because there is no “gemini command-line tool” at the moment.
This step-by-step approach ensures a successful API call in Cloud Shell. 🚀
Answer 13.
The correct answer is:
bq mk --dataset --location=US gemini_demo
Explanation:
bq mk→ Command to create a resource in BigQuery.--dataset→ Specifies that the resource being created is a dataset.--location=US→ Sets the dataset’s location to the US multi-region.gemini_demo→ The name of the dataset being created.
Why the other options are incorrect?
bq mk --dataset --location=US --dataset_name=gemini_demo
❌--dataset_nameis not a valid flag inbq mk.bq mk --dataset --location=MULTI_REGION:US gemini_demo
❌MULTI_REGION:USis not a valid location format in BigQuery; simply usingUSis correct.bq mk --dataset --location=us --dataset_id=gemini_demo
❌--dataset_idis not a valid flag for dataset creation. Also,usshould be uppercase (US).bq mk --dataset --region=US gemini_demo
❌--regionis not a valid flag; it should be--location.
Final Answer:
Use this command to correctly create the dataset:
bq mk --dataset --location=US gemini_demo
Answer 14.
The correct answer is:
ML.GENERATE_TEXT
Explanation:
ML.GENERATE_TEXTis specifically designed to integrate Generative AI models into BigQuery ML.- It allows users to perform language tasks such as content generation, text summarization, and sentiment analysis using remote AI models.
- This function is ideal for processing large text datasets, such as customer reviews, within BigQuery.
Why are the other options incorrect?
ML.FORECAST
❌ Used for time series forecasting, not for text generation.ML.PREDICT
❌ Used to make predictions based on a trained ML model but does not generate text.ML.DETECT_ANOMALIES
❌ Used for detecting anomalies in numerical datasets, not for text processing.
Final Answer:
Use ML.GENERATE_TEXT for sentiment analysis and text summarization with Generative AI in BigQuery ML. 🚀
Answer 15.
The correct answer is:
- “A prompt that asks the model to perform a task without giving any specific examples, relying on its general knowledge, like asking it to summarize a topic.”
Explanation:
- Zero-shot prompting refers to giving an AI model a task without providing any examples.
- The model relies entirely on its pre-trained knowledge to generate a response.
- Example: Asking “Summarize the benefits of remote work.” without showing any sample summaries.
Why are the other options incorrect?
- “A prompt that includes a few examples to guide the model’s generation…“
❌ This describes few-shot prompting, not zero-shot prompting. - “A prompt that provides a large dataset of text without specific instructions…“
❌ This is not a standard prompt technique; models need specific instructions to generate relevant responses. - “A prompt that gives the model one example of the desired input-output pair…“
❌ This describes one-shot prompting, not zero-shot prompting.
Final Answer:
Zero-shot prompting is when the AI is asked to perform a task without any prior examples, relying only on its pre-existing knowledge. 🚀
Answer 16.
The correct answer is:
- “A prompt that asks the model to perform a task without giving any specific examples, relying on its general knowledge, like asking it to summarize a topic.”
This accurately describes zero-shot prompting, where the model completes a task based solely on its pre-existing knowledge, without any prior examples provided in the prompt.
Answer 17.
The correct answer is:
- “Set up billing alerts to notify you when spending reaches a certain threshold that you define.”
This is the most proactive approach because it allows you to monitor costs in real-time and take action before exceeding your budget. Regularly checking the billing console is helpful but reactive, while exporting data to BigQuery is more for detailed analysis rather than immediate cost control. Negotiating discounts may help long-term but doesn’t directly address short-term spending management.
Answer 18.
The correct answers are:
- Code cells, where they can write and execute Python or R code for data manipulation and analysis.
- Output of executed code, including tables, charts, and other visualizations generated by their code.
- Visualizations (plots, graphs) created from their data, allowing for interactive exploration of results.
-
Markdown cells, where they can add formatted text, headings, and explanations to document their analysis.
- Version control history is not typically included within a Colab notebook itself. While Colab does have some versioning features (like saving checkpoints), it does not provide a full version control history like Git.
Answer 19.
The correct answer is:
gsutil cp data.csv gs://my-ml-bucket
This command correctly uses gsutil cp (copy) to upload the data.csv file from your local machine to the Cloud Storage bucket my-ml-bucket.
Explanation of Incorrect Options:
❌ gsutil copy data.csv gs://my-ml-bucket → Incorrect because copy is not a valid gsutil command. The correct command is cp.
❌ gsutil put data.csv gs://my-ml-bucket → Incorrect because put is not a valid gsutil command.
❌ gsutil mv data.csv gs://my-ml-bucket → Incorrect because mv (move) would remove the file from the local machine after copying, which isn’t required for uploading.
Answer 20.
The correct answer is:
- B. Nearline
Explanation:
- Nearline storage is designed for data that is accessed infrequently (about once a month or less), making it a cost-effective choice for files that are frequently accessed for 30 days and then rarely needed.
- Standard storage is optimized for frequent access but is more expensive for long-term storage.
- Coldline is intended for very infrequent access (once a year or less), which may not be ideal since the images are accessed within the first month.
- Archive is the lowest-cost option but is best for long-term archival storage with almost no access, making it too restrictive for this use case.
Since the images are accessed frequently for the first 30 days but rarely after, Nearline is the best balance of cost and accessibility.
Answer 21.
The correct answer is:
:wq!
Explanation:
:wq!writes (saves) the changes and quits Vim forcefully.:wq(without!) also works in most cases unless there are permission restrictions.
Why the other options are incorrect:
❌ Ctrl+S and then :q → Ctrl+S does not save in Vim; it may freeze the terminal. :q alone exits but does not save changes.
❌ :save and then :quit → :save is not a valid Vim command. The correct command for saving is :w.
❌ ctrl + o + x → This is not a valid Vim command for saving and exiting.
Thus, :wq! is the correct choice to save and exit Vim in Cloud Shell. 🚀